


DISCIPLINE - COMPUTER SCIENCE

DISCIPLINE – COMPUTER SCIENCE
TYPE OF STUDY – WORKSHOPS
Biometrics is currently a rapidly growing scientific area, exploring various ways to identify individuals through their unique biological characteristics. The aim of the workshop is to present the modern methods of biometric verification and identification of persons. During the workshop, many issues closely related to biometrics will be discussed, such as the classification of biometric data based on selected machine learning methods.
The problem of occurrence of incomplete and unbalanced data will also be discussed as well as an ensemble classifier architecture that enables direct (without any data modification) classification of such data. Theoretical background and selected practical applications of fuzzy sets and systems such as cooperation of fuzzy systems with artificial neural networks will be presented. An important part of biometric methods are methods based on Fourier and Haar transforms. The mathematical basis of both methods will be discussed, as well as practical software solutions.
Since the skilful extraction of biometric features and their analysis is an important element of person recognition, the workshop will cover the above aspects on examples of biometric features such as lip prints or voice analysis. Tools and techniques for the extraction and analysis of biometric features will be presented.
One of the most elusive goals in computer aided-design is artistic design and pattern generation. Pattern generation involves diverse aspects: analysis, creativity and development. The designer has to deal with all of these aspects in order to obtain an interesting pattern. Usually, most work during the design stage is carried out by a designer manually. Therefore, it is highly useful to develop methods (e.g., automatic, semi-automatic) that will assist pattern generation and make the whole process easier. The aim of the workshop will be the introduction of two different approaches to this problem and an attempt to combine them into one, two-staged process. In the first stage, we will use the dynamics of discrete dynamical systems, e.g., polynomiography, Mandelbrot and Julia sets etc., which have a wide range of possibilities in generating very complex patterns. The second stage will consist of the use of deep learning, namely, the use of neural style transfer, to transfer the style of the patterns from the first stage to any given image. The final result will consist of a given image created in a style of the selected dynamical system.
The research concerns analyzing the quality, length, and other parameters of decision rules generated using selected machine learning methods. There are many approaches to generating decision rules in the literature, e.g. rules generated from decision trees or rules generated using the rough set approach. In both of these issues, many variants are distinguished (different splitting criteria in decision trees, tree structures, different approaches in the area of rough sets, rules based on reducts). The generated decision rules should be as short (minimal) as possible, present non-trivial dependencies – new knowledge and guarantee high-quality classification of new unknown objects. In real applications, having a large amount of data from which we generate decision rules, the number of created rules is often so large that it is necessary to group decision rules to improve the effectiveness of decision-making systems. Thanks to the cluster analysis algorithms, it is possible to create complex, e.g. hierarchical, rule base structures and to discover hidden knowledge in obtained groups of similar rules or identified outliers rules (deviations in rules).
A summer school student will have the opportunity to learn about the methods of generating decision rules and assessing their quality using various measures. The student will learn various methods of constructing decision rules and classifying data with their use. The student will conduct research and comparisons of the quality of decision rules generated by different approaches. Both real data and those downloaded from various repositories will be used. The student will participate in experimental research, for example, on data: soil type recognition based on satellite photos, vehicle type recognition based on the characteristics obtained from the photo, and plant disease identification.
Covered issues:
- Decision tree construction algorithms: ID3, CART.
- Criteria for splitting: Gini index, Twoing criterion, entropy.
- Prepruning and postpruning trees.
- Generating rules from decision trees.
- Rough sets, feature reduction – reducts, superreducts.
- Rule generation algorithms using rough sets, including exhaustive algorithm, rule generation approach based on reducts.
- Rule quality assessment measures: rule length, support, number of rules, classification quality.
- Decision rule clustering algorithms: creating clusters of similar rules, forming cluster representatives, visualizing rule clusters, assessing the quality of rule clusters as well as detecting outliers rules (deviations in data).
In recent years, there has been a significant growth of new techniques managing lower-order heuristics (metaheuristics) within optimization applications. Between 2005 and 2013, more than 10 new techniques have emerged that do not add anything new as a technique for searching the solution space, nor are they significantly faster, or more versatile, or more efficient than the oldest ones (Fig. 1)

Fig. 1 The most prominent metaheuristic techniques according to Wikipedia (up to April 8, 2013)
Therefore, the question can be asked as to what direction the latest implementations of these techniques should take, which would significantly accelerate the progress of new applications of the aforementioned nature-inspired techniques (Fig. 2) 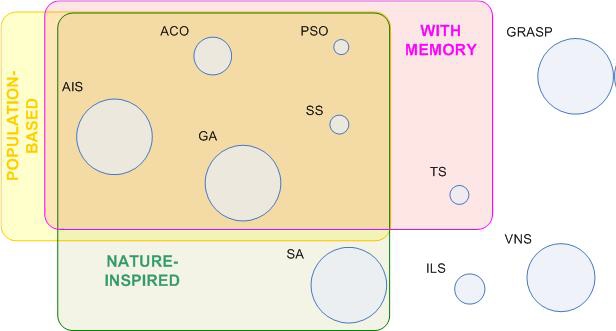
Fig. 2. Major metaheuristics grouped by different criteria. Circle size is proportional to the number of citations in Google Scholar from 2006 to 2015 (March 15, 2016)
Given the high growth (Fig.3) of machine learning work, it becomes expedient to find solutions that would significantly reduce the potential search area and significantly target this search to suboptimal regions in metaheuristic algorithms.

Fig. 3. Evolution of the number of papers devoted to Machine Learning and metaheuristics in the area of statistics and data mining ((1880 and 785 in 2015, respectively). (as of March 15, 2015)

Fig. 4. Classification of metaheuristics and machine learning of various applications
Recent work in this area has shown the rather low effectiveness of classical metaheuristics in non-academic problems. Therefore, there is an increasing focus in the academic community on new, well-developed benchmarks for testing metaheuristic algorithms and on elevating the role of learning in these approaches by using a memory model, either total or partial, or hybridizing with local search and data mining techniques. This is to increase the effectiveness of these techniques, not only in problems of large databases, but also in problems related to cryptanalysis, recommendation or other practical problems of great importance today, related to transport networks, applications in medicine, logistics, etc.
Part of the workshop will cover the use of machine learning algorithms (clustering algorithms) to manage better a large set of rules that are subject to inference in expert systems (rule-based decision support systems). The appropriate quality of the created rule cluster structures allows increasing the effectiveness of intelligent decision support systems.
As part of the workshop, participants will be introduced to the modern approach to data analysis, which is visual analysis. Visual analysis combines a standard approach to data processing using statistical methods and data mining techniques with modern data visualization (for example cluster analysis method) which are perfect for working with large data sets (especially multidimensional). Due to the fact that data visualization is better received by recipients than standard compilations and tables with results, visual analysis is becoming an increasingly popular form of data analysis. As part of visual analysis, the results of data analyzes are presented in the form of various types of charts, very often also interactive ones. Very often, the type and size of the analyzed data determine the choice of a specific data analysis and visualization method. The workshop aims to acquire these skills for the student. The workshop will discuss the techniques of preparing data for analysis, the analysis with selected algorithms, and then the visualization of this data.
As part of the workshop, participants will be introduced to the modern approach to data analysis, which is visual analysis. Visual analysis combines a standard approach to data processing using statistical methods and data mining techniques with modern data visualization. Due to the fact that data visualization is better received by recipients than standard compilations and tables with results, visual analysis is becoming an increasingly popular form of data analysis. As part of visual analysis, the results of data analyzes are presented in the form of various types of charts, very often also interactive ones. As part of the workshop, students will learn how to prepare data, analyze them and then prepare a visualization of the obtained results in the most accessible way for potential recipients.
Biometrics is currently a rapidly growing scientific area, exploring various ways to identify individuals through their unique biological characteristics. The aim of the workshop is to present the modern methods of biometric verification and identification of persons. During the workshop, many issues closely related to biometrics will be discussed, such as the classification of biometric data based on selected machine learning methods.
The problem of occurrence of incomplete and unbalanced data will also be discussed as well as an ensemble classifier architecture that enables direct (without any data modification) classification of such data. Theoretical background and selected practical applications of fuzzy sets and systems such as cooperation of fuzzy systems with artificial neural networks will be presented. An important part of biometric methods are methods based on Fourier and Haar transforms. The mathematical basis of both methods will be discussed, as well as practical software solutions.
Since the skilful extraction of biometric features and their analysis is an important element of person recognition, the workshop will cover the above aspects on examples of biometric features such as lip prints or voice analysis. Tools and techniques for the extraction and analysis of biometric features will be presented.
One of the most elusive goals in computer aided-design is artistic design and pattern generation. Pattern generation involves diverse aspects: analysis, creativity and development. The designer has to deal with all of these aspects in order to obtain an interesting pattern. Usually, most work during the design stage is carried out by a designer manually. Therefore, it is highly useful to develop methods (e.g., automatic, semi-automatic) that will assist pattern generation and make the whole process easier. The aim of the workshop will be the introduction of two different approaches to this problem and an attempt to combine them into one, two-staged process. In the first stage, we will use the dynamics of discrete dynamical systems, e.g., polynomiography, Mandelbrot and Julia sets etc., which have a wide range of possibilities in generating very complex patterns. The second stage will consist of the use of deep learning, namely, the use of neural style transfer, to transfer the style of the patterns from the first stage to any given image. The final result will consist of a given image created in a style of the selected dynamical system.
The research concerns analyzing the quality, length, and other parameters of decision rules generated using selected machine learning methods. There are many approaches to generating decision rules in the literature, e.g. rules generated from decision trees or rules generated using the rough set approach. In both of these issues, many variants are distinguished (different splitting criteria in decision trees, tree structures, different approaches in the area of rough sets, rules based on reducts). The generated decision rules should be as short (minimal) as possible, present non-trivial dependencies – new knowledge and guarantee high-quality classification of new unknown objects. In real applications, having a large amount of data from which we generate decision rules, the number of created rules is often so large that it is necessary to group decision rules to improve the effectiveness of decision-making systems. Thanks to the cluster analysis algorithms, it is possible to create complex, e.g. hierarchical, rule base structures and to discover hidden knowledge in obtained groups of similar rules or identified outliers rules (deviations in rules).
A summer school student will have the opportunity to learn about the methods of generating decision rules and assessing their quality using various measures. The student will learn various methods of constructing decision rules and classifying data with their use. The student will conduct research and comparisons of the quality of decision rules generated by different approaches. Both real data and those downloaded from various repositories will be used. The student will participate in experimental research, for example, on data: soil type recognition based on satellite photos, vehicle type recognition based on the characteristics obtained from the photo, and plant disease identification.
Covered issues:
- Decision tree construction algorithms: ID3, CART.
- Criteria for splitting: Gini index, Twoing criterion, entropy.
- Prepruning and postpruning trees.
- Generating rules from decision trees.
- Rough sets, feature reduction – reducts, superreducts.
- Rule generation algorithms using rough sets, including exhaustive algorithm, rule generation approach based on reducts.
- Rule quality assessment measures: rule length, support, number of rules, classification quality.
- Decision rule clustering algorithms: creating clusters of similar rules, forming cluster representatives, visualizing rule clusters, assessing the quality of rule clusters as well as detecting outliers rules (deviations in data).
In recent years, there has been a significant growth of new techniques managing lower-order heuristics (metaheuristics) within optimization applications. Between 2005 and 2013, more than 10 new techniques have emerged that do not add anything new as a technique for searching the solution space, nor are they significantly faster, or more versatile, or more efficient than the oldest ones (Fig. 1)
Fig. 1 The most prominent metaheuristic techniques according to Wikipedia (up to April 8, 2013)
Therefore, the question can be asked as to what direction the latest implementations of these techniques should take, which would significantly accelerate the progress of new applications of the aforementioned nature-inspired techniques (Fig. 2)
Fig. 2. Major metaheuristics grouped by different criteria. Circle size is proportional to the number of citations in Google Scholar from 2006 to 2015 (March 15, 2016)
Given the high growth (Fig.3) of machine learning work, it becomes expedient to find solutions that would significantly reduce the potential search area and significantly target this search to suboptimal regions in metaheuristic algorithms.
Fig. 3. Evolution of the number of papers devoted to Machine Learning and metaheuristics in the area of statistics and data mining ((1880 and 785 in 2015, respectively). (as of March 15, 2015)
Fig. 4. Classification of metaheuristics and machine learning of various applications
Recent work in this area has shown the rather low effectiveness of classical metaheuristics in non-academic problems. Therefore, there is an increasing focus in the academic community on new, well-developed benchmarks for testing metaheuristic algorithms and on elevating the role of learning in these approaches by using a memory model, either total or partial, or hybridizing with local search and data mining techniques. This is to increase the effectiveness of these techniques, not only in problems of large databases, but also in problems related to cryptanalysis, recommendation or other practical problems of great importance today, related to transport networks, applications in medicine, logistics, etc.
Part of the workshop will cover the use of machine learning algorithms (clustering algorithms) to manage better a large set of rules that are subject to inference in expert systems (rule-based decision support systems). The appropriate quality of the created rule cluster structures allows increasing the effectiveness of intelligent decision support systems.